全能繁体中文文档表格OCR识别系统
全能繁体中文文档表格OCR识别系统,聚焦繁体中文场景深度优化,具备印刷体、印刷+手写混合体双重识别能力,兼顾文档与表格一体化智能处理,为各类繁体中文使用场景提供高效、精准的信息提取解决方案。
对此产品感兴趣?
产品详情
在港澳台地区政务办理、企业办公、跨境贸易及古籍档案整理等场景中,繁体中文文档与表格是核心信息载体。传统人工录入模式不仅耗时耗力,还易因繁体字形复杂、排版多样(竖排/横排)、手写批注混杂等问题出现信息错漏,严重制约数字化转型进度。全能繁体中文文档表格OCR识别系统,聚焦繁体中文场景深度优化,具备印刷体、印刷+手写混合体双重识别能力,兼顾文档与表格一体化智能处理,为各类繁体中文使用场景提供高效、精准的信息提取解决方案。
核心能力:深耕繁体中文,兼顾文档与表格识别
系统依托海量繁体中文样本训练与深度学习算法优化,精准适配繁体中文独特字形结构、排版习惯,彻底攻克繁体识别难点,同时实现文档与表格的同步高效处理。
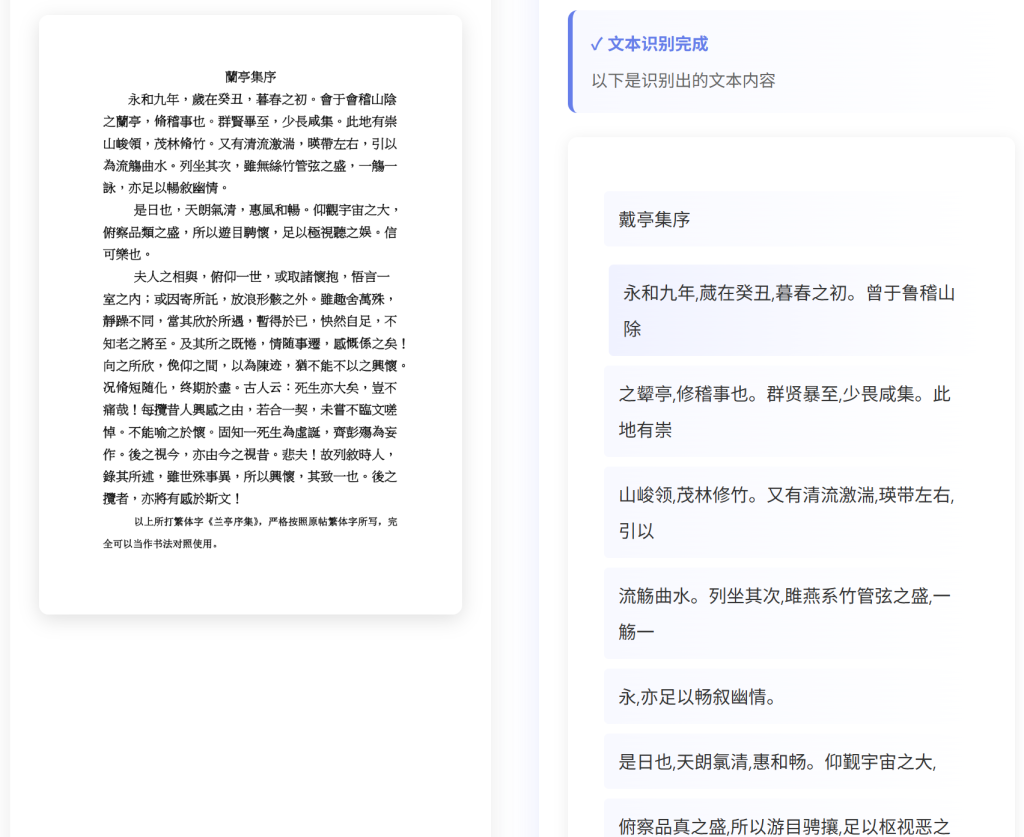
1. 全类型繁体中文精准识别
全面支持繁体中文印刷体、印刷+手写混合体识别,适配各类复杂文本形态:
- 印刷体识别:完美适配竖排古籍、横排政务公文、企业年报、财务报表、跨境报关单等规范印刷文本,可精准还原版面结构,提取户号、金额、条款、证件号等关键信息,无惧字体、字号差异及排版变体。
- 混合体识别:高效区分印刷内容与手写笔迹,轻松识别带手写签名的合同、手写批注的审批表、手工填写的出入库单、繁体病历等混合文本,精准捕捉手写签名、修改意见、填写内容,解决繁体手写识别精度低的行业痛点。
2. 文档表格一体化处理
具备先进的版面分析与结构还原能力,可自动区分繁体中文文档中的文字、表格、图片元素,实现“文档提取+表格解析”一步到位:
- 表格识别:精准识别繁体中文表格的表头、行列分布,还原复杂表格结构,提取数字、日期、备注等结构化数据,适配工程验收记录、档案卷内目录、财务凭证等各类表格。
- 文档处理:支持多页混贴自动切分、竖排文本智能适配,可提取合同条款、政策要点、古籍文字等非结构化信息,输出可编辑格式,无需人工二次整理。
核心功能亮点:适配复杂场景,兼顾灵活与安全
1. 复杂场景自适应,无需人工预处理
内置强大的图像处理引擎,可智能应对光照不均、图像模糊、页面倾斜、反光、褶皱、复杂背景等实际场景问题,支持自动旋转、倾斜校正、背景降噪、裁边优化,无论是手机拍摄、扫描仪扫描的文件,还是老旧褪色的繁体档案,都能稳定输出高精度识别结果,大幅降低操作门槛。
2. 灵活输出与个性化适配
支持JSON、XML、WORD、XLS、双层PDF等多种格式导出,可直接对接企业ERP、CRM、政务系统,无缝融入现有业务流程。同时搭载智能模板训练平台,可针对港澳台地区专属表单、行业定制表格(如不动产登记申请表、跨境贸易单据)定制识别模板,进一步提升特定场景识别精度。
3. 安全部署,适配多元环境
兼容Windows、Linux操作系统,全面适配鲲鹏、飞腾等国产CPU及国产GPU,支持纯CPU环境部署以控制成本。提供企业内网私有化部署方案,全程保障繁体中文敏感数据(如政务信息、商业合同、个人档案)安全,符合港澳台地区及跨境业务数据合规要求。
产品优势:重塑繁体场景办公效率
- 精准高效:秒级识别响应,单份/批量处理效率远超人工,繁体印刷体识别准确率达99%以上,混合体识别精度领先行业,大幅减少校对成本。
- 场景适配广:无需专业采集设备,适配政务、金融、档案、跨境贸易、工程建筑等多领域,覆盖竖排/横排、新旧文档、纯印刷/混合手写等全场景。
- 易用省心:操作流程简单,无需专业技术培训即可上手,模板定制功能满足个性化需求,适配港澳台地区用户使用习惯。
- 信创兼容:全面支持国产化软硬件体系,符合政企单位国产化建设及数据安全规范。
适用场景:赋能全行业繁体中文数字化
1. 政务办公领域
应用于港澳台地区户口迁移、不动产登记、行政审批等业务,快速识别繁体中文申请表、审批公文、档案材料,加速业务办理流程,减少群众排队等待时间。
2. 跨境贸易领域
处理中港澳台及海外繁体中文合同、报关单、发票、装箱单等单据,自动提取贸易信息,加速清关结算,打破跨境业务信息处理壁垒。
3. 档案管理领域
适配古籍档案、企业历史资料、军政档案等繁体文本数字化加工,将竖排、老旧、模糊的繁体文档表格转化为可检索电子数据,实现档案智能管理。
4. 金融财务领域
识别繁体中文财务报表、银行回单、保险保单、信贷申请表等,应用于跨境金融、港澳台本地金融业务,自动化录入数据,控制业务风险。
使用建议
为确保最佳识别效果,建议上传文件大小不超过5M,扫描件分辨率设置为300DPI,尽量保证繁体文字清晰、无严重遮挡或污渍。系统支持前期部署测试与模板定制优化,可根据具体业务场景调整识别方案,如需体验或定制专属服务,欢迎随时咨询!

