医保报销和电子病历OCR识别
医保报销
自动识别快递单信息,实现智能分拣,提升分拣效率300%,降低错误率。
对此方案感兴趣?
方案详情
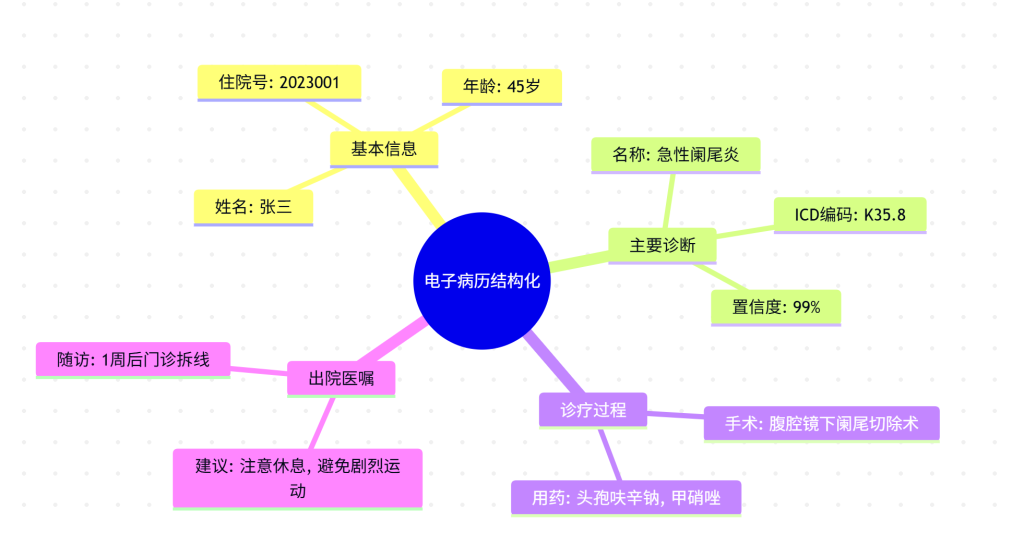
电子病历(EMR)的识别与之前的“医疗票据”识别有本质区别。票据处理的是固定版式的表格”,而电子病历处理的是“半结构化或非结构化的自然语言文本”。
这不仅需要 OCR(光学字符识别),更需要强大的 NLP(自然语言处理) 和 医疗知识图谱 来理解医学语义。
以下是针对 “医院电子病历识别与结构化” 的完整技术方案与架构图。
一、 核心难点:为什么病历识别很难?
- 版式极度复杂: 包含大段文字(现病史)、表格(检验结果)、键值对(生命体征),且排版无统一标准。
- 医学语义理解: 需要从大段文字中提取出“诊断”、“症状”、“药品”、“手术”以及它们之间的关系(例如:否定词识别,“无高血压史”不能识别成“高血压”)。
- 术语归一化: 医生写的“大三阳”、“乙肝”需要统一映射为标准 ICD-10 编码。
二、 技术架构图:从图像到医疗数据
这是电子病历处理的专用流水线(Pipeline)。

三、 关键步骤详解
1. 版面分析 (Layout Analysis) —— 最关键的一步
病历不是从左读到右那么简单。系统必须先“看懂”版面:
- 页眉/页脚去除: 避免把医院名字误识别为病情。
- 分栏处理: 很多出院小结是左右分栏的,如果不切分直接横向OCR,文字顺序会乱(例如左边读一半直接读到右边)。
- 段落识别: 自动定位“主诉”、“现病史”、“出院诊断”等关键段落的起止坐标。
2. 医学实体识别 (Medical NER)
这是从文本中“抓重点”的过程。
- 输入: “患者因突发胸痛2小时入院,伴大汗淋漓,既往有高血压病史10年。”
- 输出(实体标签):
[症状]:胸痛、大汗淋漓[时间]:2小时[疾病]:高血压[修饰词]:既往(这很重要,代表不是本次的确诊)
3. 结构化与归一化 (Structuring & Normalization)
将提取的信息转化为数据库可存取的标准格式。
- 原文: “二甲双胍”
- 归一化: 通用名
Metformin,ATC编码A10BA02。 - 原文: “阑尾切除术”
- 归一化: 手术编码
47.0901。